Introduction
ResNet, which stands for Residual Network, is a revolutionary deep learning model created by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun in their 2015 paper “Deep Residual Learning for Image Recognition.” ResNet tackles big challenges in training very deep neural networks, like the vanishing gradient problem, and has achieved amazing results in various computer vision tasks.
Why ResNet?
The Need for Deeper Networks
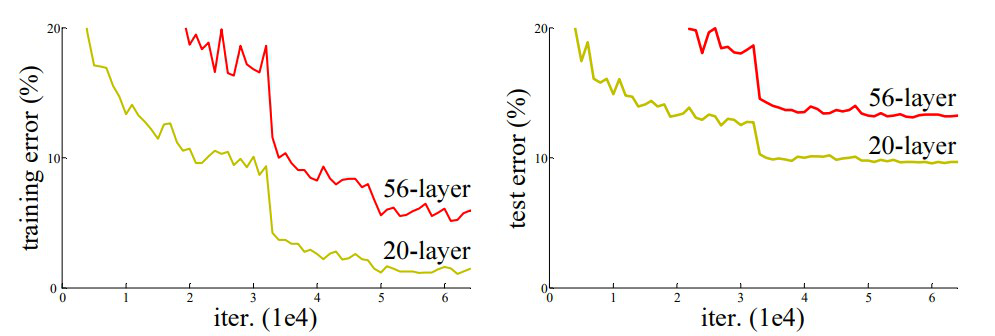
Traditional Convolutional Neural Networks (CNNs) face performance issues when the network depth increases. This isn’t because of overfitting but rather an optimization challenge where adding more layers makes the network harder to train effectively.
The Vanishing Gradient Problem
It has been found that there is a maximum threshold for depth with the traditional CNN. When neural networks get deeper, the gradients used to update weights during backpropagation become very small, leading to negligible updates. This is known as the vanishing gradient problem and it makes training very deep networks difficult.
The Solution: Residual Blocks
ResNet introduces residual learning through residual blocks. Instead of expecting each layer to directly fit a desired mapping, residual blocks allow layers to fit a residual mapping. It’s easier to optimize the residual mapping than the original, unreferenced mapping.
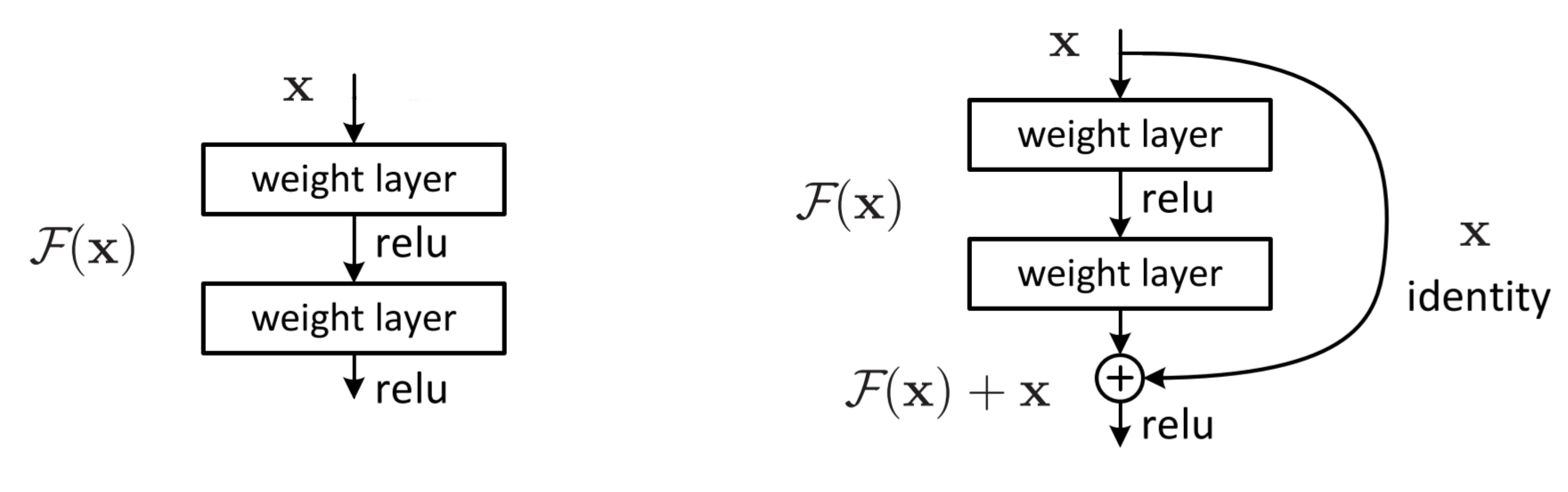
Residual Block Structure
A typical residual block in ResNet has two or more convolutional layers followed by batch normalization and ReLU activation. The input to the block is added directly to the output of the stacked layers (this addition is the “shortcut connection”), creating a residual connection.
Mathematical Representation
If the input is $ ( x ) $ and the desired output is $( H(x) ) $, a residual block models this as: $\ H(x) = F(x, {W_i}) + x $ where $ ( F(x, {W_i}) ) $ represents the residual mapping to be learned.
ResNet Architecture
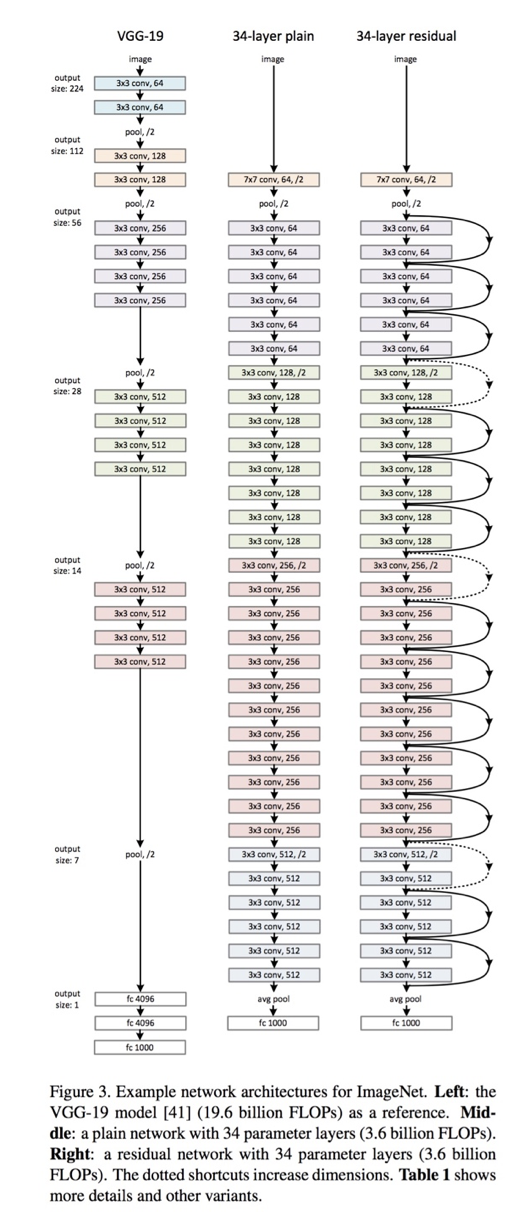
ResNet architectures come in various depths, such as ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-152~201, indicating the number of layers. These architectures stack residual blocks to create deep networks that can effectively learn complex features.
Key Components
- Convolutional Layers: Extract features from the input image.
- Batch Normalization: Normalizes the output of each convolutional layer, stabilizing and accelerating training.
- ReLU Activation: Introduces non-linearity.
- Residual Connections: Add the input of the block to the output, allowing the network to learn residual mappings.
Achievements of ResNet
ResNet won first place in the ILSVRC 2015 classification competition with a top-5 error rate of 3.57% using an ensemble model. It also won first place in the ImageNet Detection, ImageNet Localization, COCO Detection, and COCO Segmentation tasks in the ILSVRC and COCO 2015 competitions.
Notably, replacing VGG-16 layers in Faster R-CNN with ResNet-101 layers led to a 28% relative improvement.
Transfer Learning or Fine-tuning
ResNet’s pre-trained models are often used for transfer learning, where a model trained on a large dataset like ImageNet is fine-tuned for specific tasks with smaller datasets.
This approach significantly reduces training time and improves performance.