Introduction
Image segmentation is a crucial technique in computer vision, enabling the division of an image into multiple meaningful and homogeneous regions or objects based on their inherent characteristics, such as color, texture, shape, or brightness. We delve into two powerful deep learning models for image segmentation: Fully Convolutional Networks (FCN) and U-Net.
Fully Convolutional Networks (FCN)
Fully Convolutional Networks (FCNs) are a class of neural networks designed specifically for semantic segmentation. Unlike traditional Convolutional Neural Networks (CNNs) that produce a single label for the entire image, FCNs output a segmentation map where each pixel is classified into a particular category.
Architecture
The architecture of an FCN is based on an encoder-decoder structure:
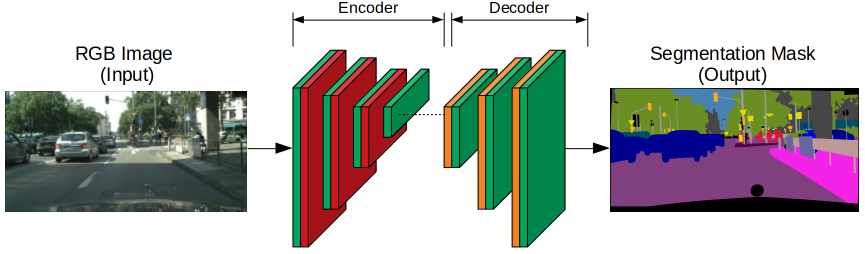
-
Encoder (Downsampling Path): This part of the network extracts complex features from the input image through a series of convolutional and pooling layers. The spatial resolution is reduced while increasing the depth of the feature maps, allowing the network to capture high-level semantic information.
-
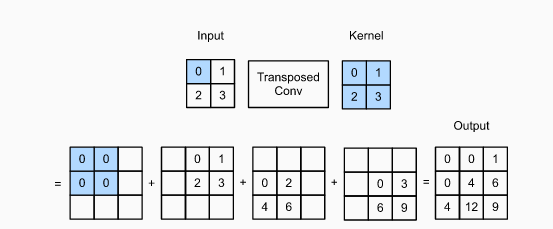
Decoder (Upsampling Path): The decoder part of the network upscales the reduced-resolution feature maps back to the original image size. This is achieved through transposed convolution layers (also known as deconvolution layers), which learn the appropriate strides and padding to reconstruct the high-resolution segmentation map.
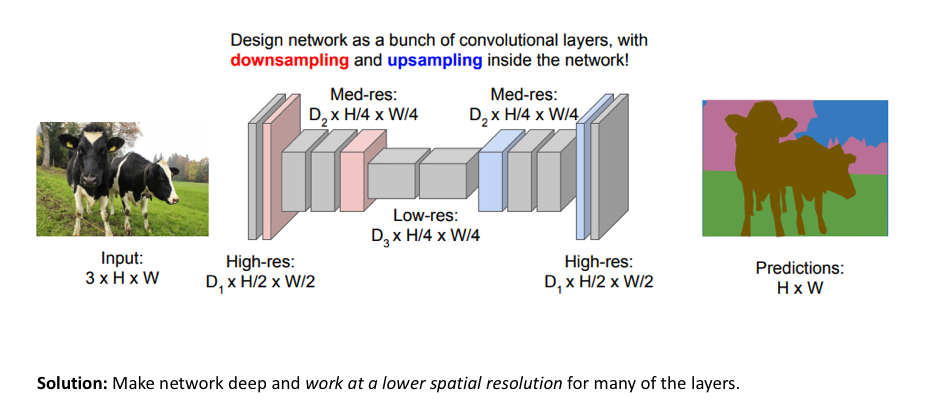
Key Concepts
- Pooling (Downsampling): Pooling layers reduce the spatial resolution of the feature maps, which helps in capturing invariant features and reducing computational complexity. Common types include max pooling and average pooling.
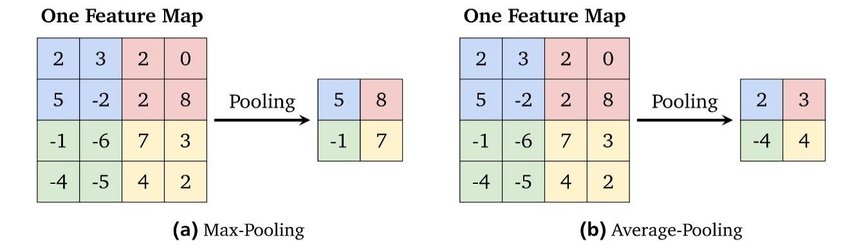
- Unpooling (Upsampling): Pooling converts a patch of values to a single value, whereas unpooling does the opposite, converts a single value into a patch of values.
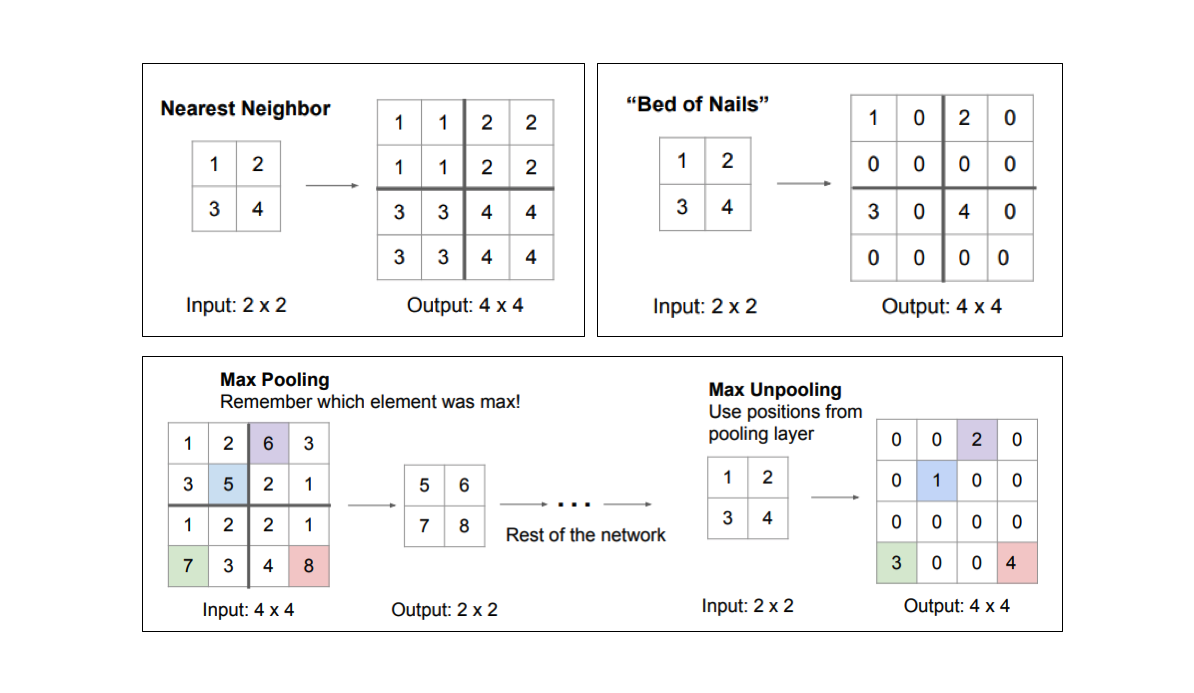
- Transposed Convolution (Upsampling): are used to increase the spatial resolution of the feature maps, essentially reversing the effect of pooling layers to reconstruct the detailed segmentation map.
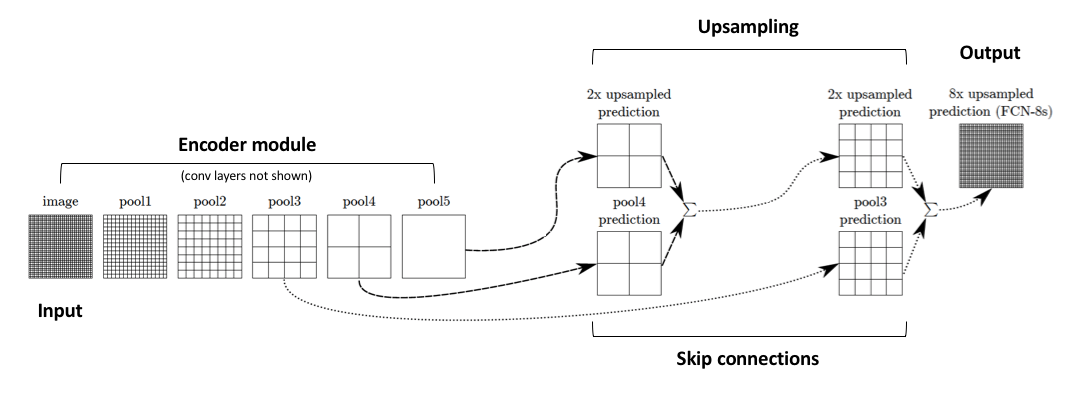
- Skip Connections: One major issue with in-network downsampling in a FCN is that it reduces the resolution of the input by a large factor, thus during upsampling it becomes very difficult to reproduce the finer details even after using sophisticated techniques like Transpose Convolution.
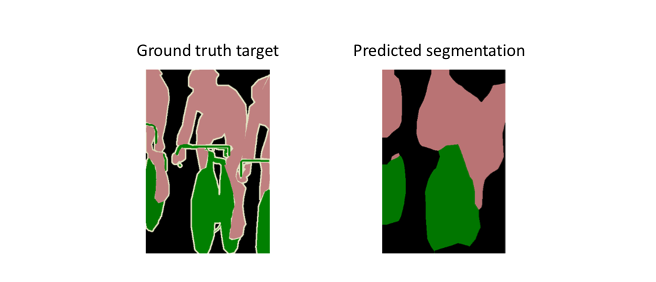
One-way to deal with this is by adding skip connections in the upsampling stage from earlier layers and summing the two feature maps. These connections transfer features from the encoder directly to the corresponding decoder layers, enabling the network to recover fine-grained details and produce more accurate segmentation boundaries.
U-Net
Overview
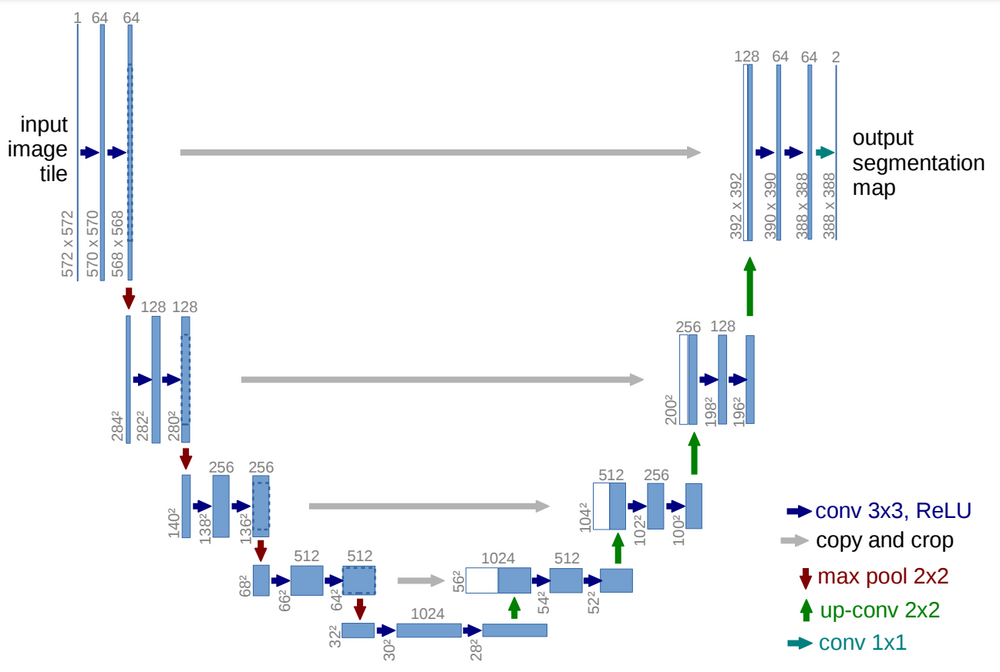
U-Net is a specialized neural network architecture designed for biomedical image segmentation, introduced by Olaf Ronneberger, Philipp Fischer, and Thomas Brox in 2015. Its distinctive U-shaped design, which features a symmetric encoder-decoder structure, has made it a popular choice in various medical image analysis tasks due to its impressive performance and efficiency.
Architecture
The U-Net architecture consists of two main parts:
-
Encoder (Contraction Path): Similar to FCN, the encoder part of U-Net captures high-level features through a series of convolutional and pooling layers. Each block typically consists of two 3x3 convolution layers followed by a ReLU activation function and a 2x2 max pooling layer.
-
Decoder (Expansion Path): The decoder part upscales the feature maps to the original image size using transposed convolutions. At each upsampling step, the decoder concatenates the feature maps from the corresponding encoder layer via skip connections, providing rich contextual information for precise segmentation.
Key Concepts
-
Skip Connections: By concatenating the feature maps from the encoder to the decoder at each corresponding level, U-Net can leverage both high-level and low-level features, resulting in better localization and segmentation accuracy.
-
Data Augmentation: Given the often limited availability of annotated data in medical imaging, U-Net heavily relies on data augmentation techniques to enhance the diversity of the training dataset. This includes operations like rotations, flips, and elastic deformations.