Introduction
EfficientNet is an advanced deep learning model introduced by Mingxing Tan and Quoc V. Le from Google Research, Brain team, in their paper “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”. EfficientNet solves the common problem of balancing accuracy and resource consumption in deep learning models by using a novel technique called compound scaling.
Why EfficientNet?
The Challenge of Traditional Models
Traditional deep learning models often face a trade-off between accuracy and resource use. Making a model more accurate usually means making it larger, which requires more computational power and memory. EfficientNet tackles this challenge effectively.
The Solution: Compound Scaling
EfficientNet introduces compound scaling, which scales three critical dimensions of a neural network: width, depth, and resolution. This scaling method ensures that the model is both efficient and accurate.
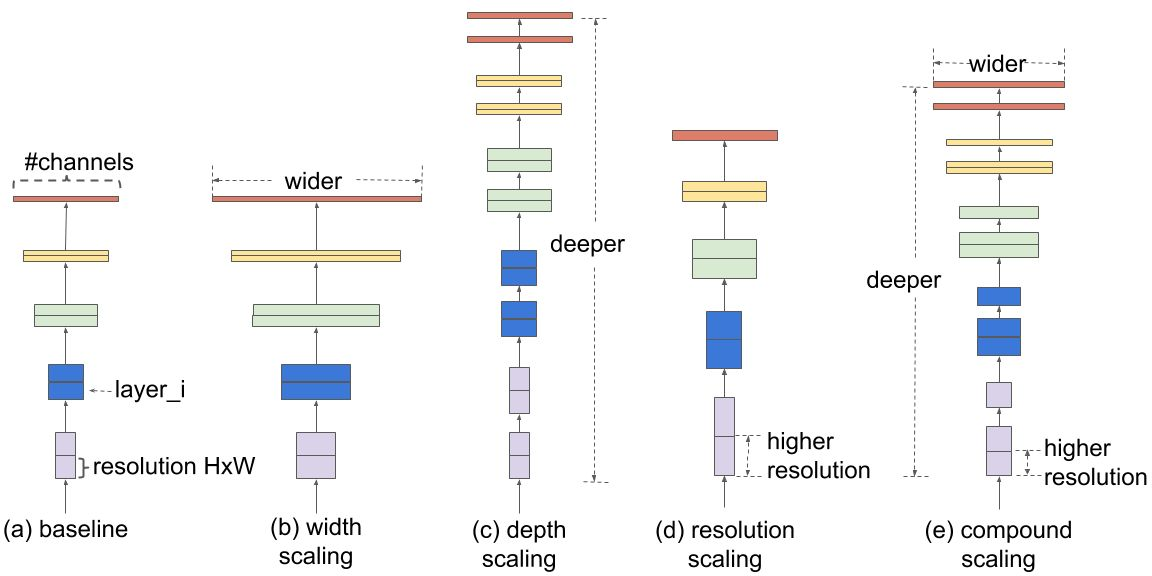
Width Scaling
Width scaling refers to the number of channels(third dimension of an image) in each layer of the neural network. Increasing the width helps the model capture more complex patterns and features, leading to improved accuracy. Conversely, decreasing the width results in a more lightweight model suitable for environments with limited resources.
Depth Scaling
Depth scaling involves the total number of layers in the network. Deeper models can capture more intricate data representations but require more computational resources. Shallower models are computationally efficient but might sacrifice accuracy.
Resolution Scaling
Resolution scaling adjusts the size of the input images. Higher-resolution images provide more detailed information, potentially improving performance. However, they also need more memory and computational power. Lower-resolution images consume fewer resources but may lose fine-grained details.
Mathematical Explanation of Compound Scaling
EfficientNet uses a simple yet effective method to scale up models. The scaling method is guided by a compound coefficient $( \phi )$ which uniformly scales network width, depth, and resolution:
$$
\text{depth:} \quad d = \alpha^\phi
$$
$$
\text{width:} \quad w = \beta^\phi
$$
$$
\text{resolution:} \quad r = \gamma^\phi
$$
where $( \alpha )$, $( \beta )$, and $( \gamma )$ are constants determined through a small grid search and $( \phi )$ is a user-specified coefficient that controls how much to scale each dimension. The idea is to balance all three dimensions rather than scaling one aspect alone.
Grid Search for EfficientNet
The process of determining the constants $( \alpha )$, $( \beta )$, and $( \gamma )$ involves two main steps:
Step 1: Baseline Network
Assume twice the resources are available and set $( \phi = 1 )$. Perform a small grid search for $( \alpha )$, $( \beta )$, and $( \gamma )$ based on equations 2 and 3 from the original paper. Specifically, the best values for EfficientNet-B0 are found to be $( \alpha = 1.2 )$, $( \beta = 1.1 )$, and $( \gamma = 1.15 )$ under the constraint:
$$
\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2
$$
Step 2: Compound Scaling
Fix $( \alpha )$, $( \beta )$, and $( \gamma )$ as constants and scale up the baseline network with different $( \phi )$ values using the equation:
$$
\text{New Depth} = \alpha^\phi \times \text{Baseline Depth}
$$
$$
\text{New Width} = \beta^\phi \times \text{Baseline Width}
$$
$$
\text{New Resolution} = \gamma^\phi \times \text{Baseline Resolution}
$$
This method is used to obtain EfficientNet-B1 up to B7 models.
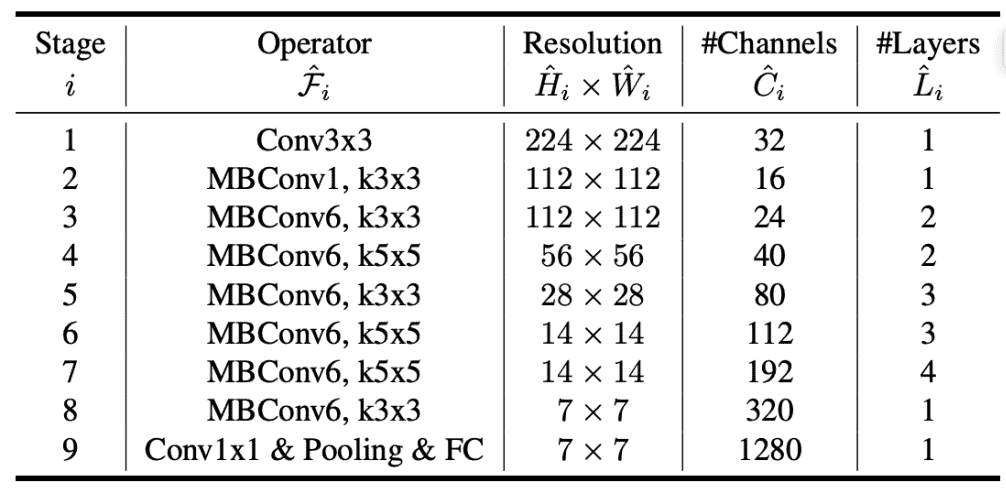
EfficientNet Architecture
EfficientNet uses Mobile Inverted Bottleneck (MBConv) layers, which combine depth-wise separable convolutions and inverted residual blocks. This architecture helps achieve high performance with fewer resources.
- Inverted Residual Blocks(aka MBConv Block) Layers: EfficientNet uses these layers for efficient feature extraction.
- Compound Scaling: Scales width, depth, and resolution uniformly.
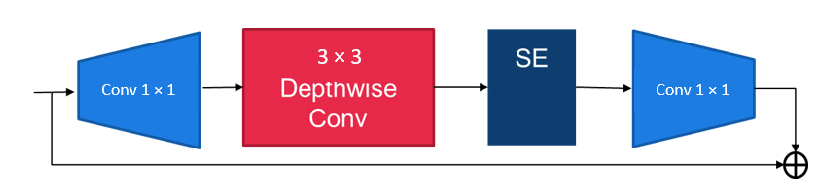
Inside an Inverted Residual Block:
- 1x1 Convolution (Expansion): Expands the number of channels.
- Depthwise Convolution: Applies lightweight filters to each channel independently.
- Squeeze-and-Excitation (SE): Assigns importance weights to each channel.
- 1x1 Convolution (Projection): Reduces the number of channels back to the original size.
- Residual Connection: Adds the original input back to the output.
EfficientNet models have set new benchmarks for accuracy while being more resource-efficient than previous models. They are widely used for various computer vision tasks due to their balanced approach to scaling.
Their architectures, such as EfficientNet-B0 up to EfficientNet-B7, provide a range of options depending on the
required accuracy and available computational resources.