Convolutional Neural Networks (CNNs) are a class of deep learning models used to process and recognize patterns in images or any visual data.
We know that, Neural Networks in general are collection of neurons that are organized in layers, each with their own learnable weights and biases.
So when we say neurons, in practice we mostly mean the filters. The neuron is a complete computational unit (filter + bias+ activation). At least in PyTorch, when we specify filters=64, it means we are creating 64 complete neurons (filter + bias + activation).
def cnn_neuron(input_patch, kernel_weights, bias):
feature_response = np.sum(input_patch * kernel_weights) + bias
output = max(0, feature_response) # ReLU
return output
So below, we can see that a neuron receives multiple inputs and produces single output y.
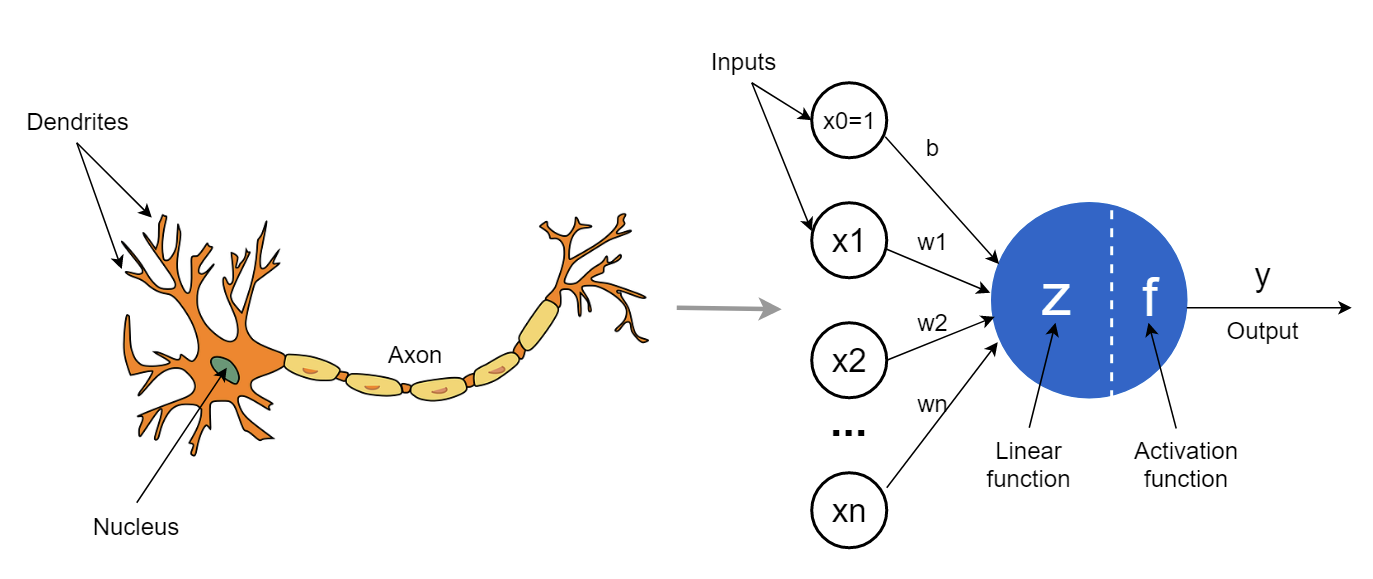
Layers: A layer consists of a collection of neurons that perform the same operation, sharing identical hyperparameters.
Kernel weights and biases: Unique to each neuron, kernel weights and biases are adjusted during the training process, enabling the classifier to adapt to the specific problem and dataset.
Key Concepts of CNN Components
Convolutional Layer
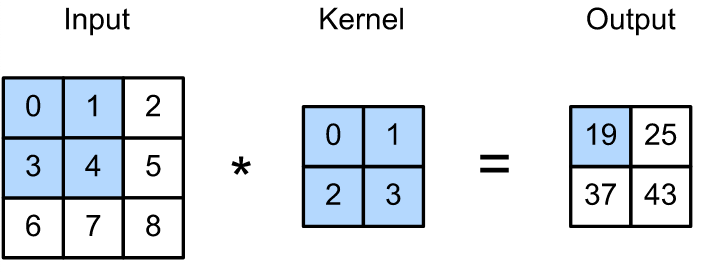
The convolutional layer applies filter(kernel) to the input image to extract features like edges and textures.
- Convolutional Layer: The primary building block of a CNN, responsible for feature extraction.
- Filter (Kernel): A small matrix that slides over the input image, performing multiplications and summations to produce a feature map.
- Feature Map (Activation Map): The result of the convolution operation, highlighting important features such as edges, textures, and patterns.
Convolution operation allows the network to learn spatial hierarchies of features automatically from low-level to high-level.
$$ (I * K)(i, j) = \sum_{m=0}^{M-1} \sum_{n=0}^{N-1} I(i + m, j + n) K(m, n) $$
- $( I )$: Input image
- $( K )$: Kernel (filter)
- $( (i, j) )$: Coordinates in the output feature map
- $( M, N )$: Dimensions of the kernel
Understanding Hyperparameters
- Kernel Size: Dimensions of the filter (e.g., 3x3, 5x5). Affects the amount of detail the filter can capture.
- Stride: Step size of the filter movement. Larger strides reduce the output size but increase computational efficiency.
- Padding: Adds zeros around the input image to maintain the output size. “Valid” means no padding, “same” keeps the output size the same as the input.
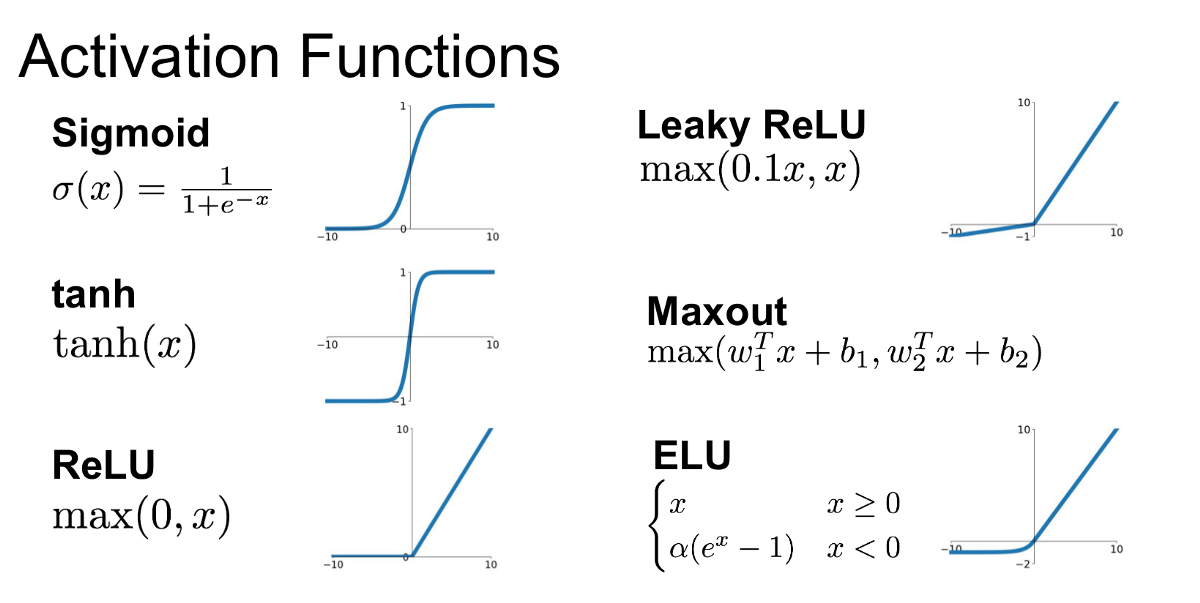
Non-Linearity (ReLU) Activation Function
- ReLU (Rectified Linear Unit): Introduces non-linearity to the model. It replaces negative values with zero, allowing the network to learn complex patterns. Activation function decides whether the neuron must be activated or not. So it means whether the neuron’s input is important to the network or not.
$$ \text{ReLU}(x) = \begin{cases} x & \text{if } x > 0 \\ 0 & \text{otherwise} \end{cases} $$
By setting negative values to zero, ReLU prevents the network from simply becoming a linear classifier.
Another popular activation functions:
Pooling Layers
Reduces computational complexity and helps the network become invariant to small translations of the input image.
- Max-Pooling: operation requires selecting a kernel size and a stride length. Once selected, the operation slides the kernel with the specified stride over the input retaining the most important information by selecting the maximum value within each window, effectively down-sampling the feature map.
$$ Y(i, j) = \max_{m,n} X(i \cdot s + m, j \cdot s + n) $$
- $( X )$: Input feature map
- $( Y )$: Output feature map
- $( s )$: Stride
- $( m, n )$: Window dimensions
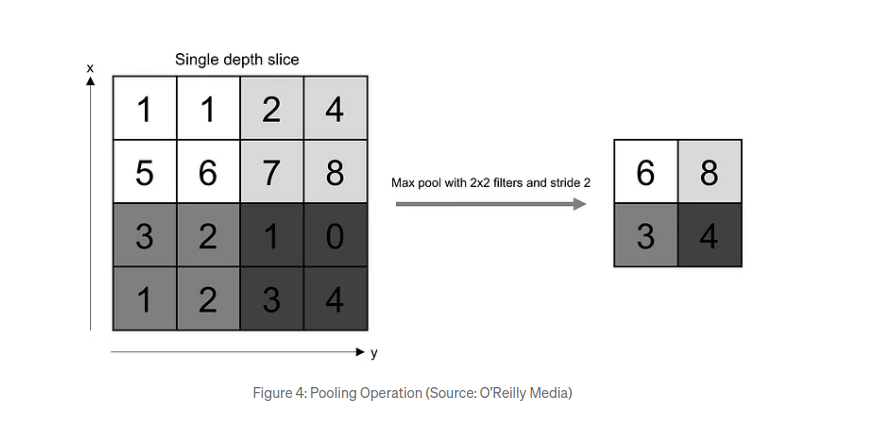
Pooling prevents overfitting.
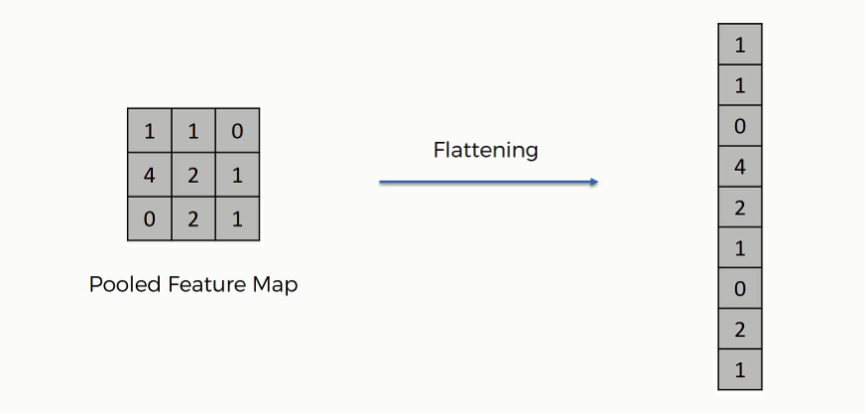
Flattening
- Flatten Layer: Converts the 2D pooled feature maps into a 1D vector for the fully connected layers. The flattened vector is fed as input to the fully connected layer to classify the image.
Fully Connected Layer
The Fully Connected Layer, also known as the dense layer, is the final layer that comes after the convolutional and pooling layers. Its purpose is to perform classification or regression tasks based on the high-level features extracted by the earlier layers of the network. In FC, all the neurons of the input are connected to every neuron of the output layer.
- Formula:
$$ y = f(W \cdot x + b) $$
- $( W )$: Weight matrix
- $( x )$: Input vector
- $( b )$: Bias vector
- $( f )$: Activation function
The fully connected layer combines the high-level features learned by the convolutional layers to output a final prediction.
Output Layer
The output layer is typically a softmax layer in classification tasks. The softmax function converts the raw output scores into probabilities.
- Softmax Function:
$$ \sigma(z_i) = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} $$
- $( z_i )$: The (i)-th element of the input vector $(z)$
- $( K )$: Number of classes
The softmax function ensures that the output probabilities sum to 1, making it easier to interpret the results as the likelihood of each class.
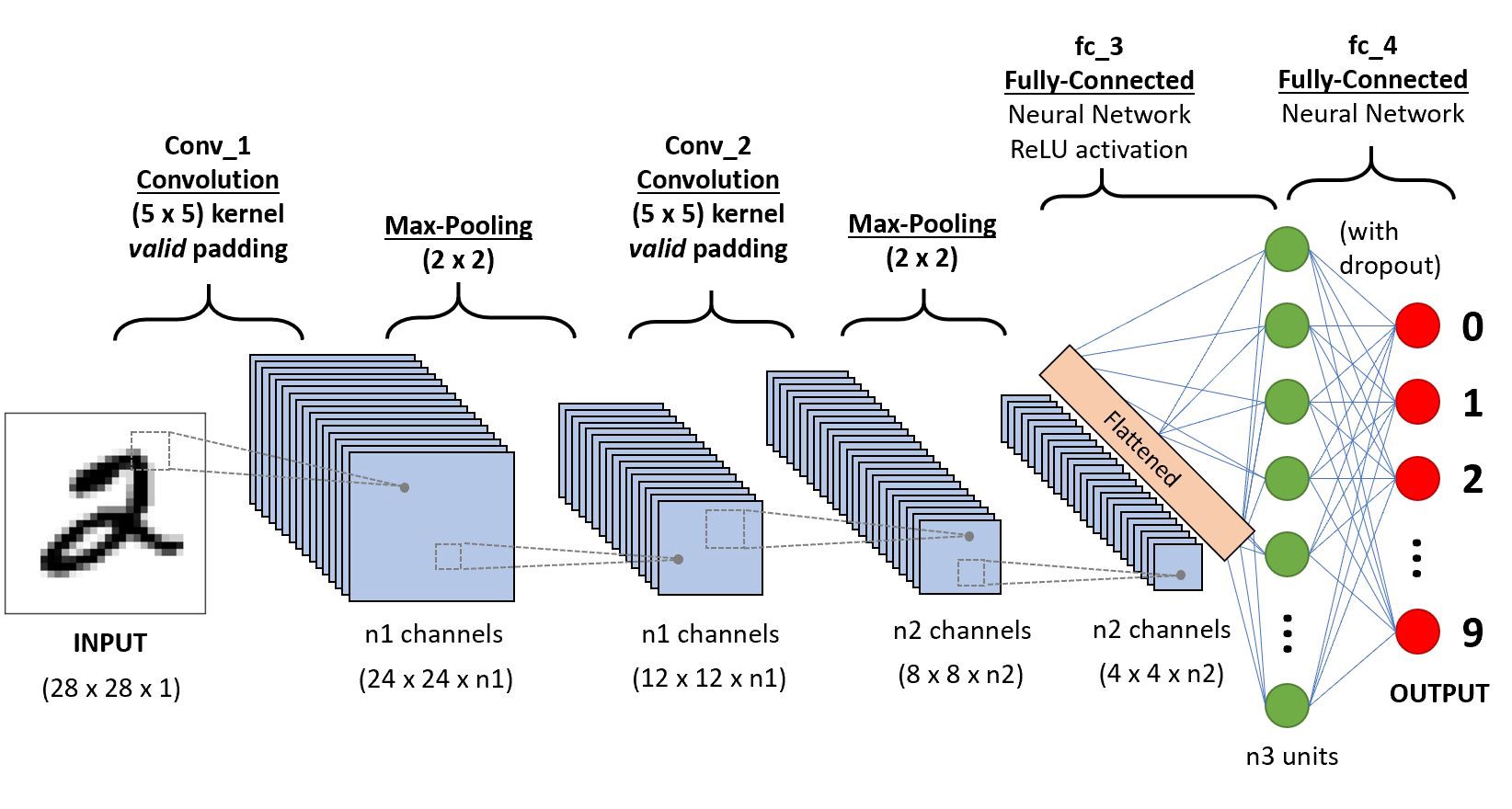
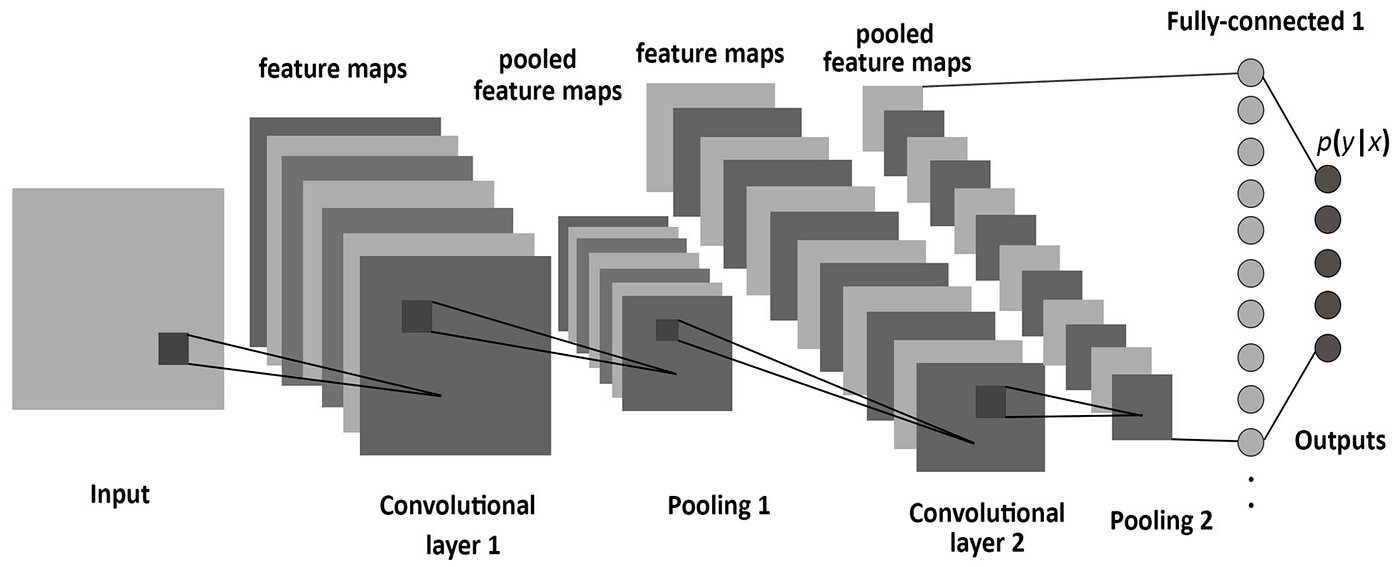
Simple Example of CNN Architecture
Here’s a simple CNN architecture for image classification:
- Input Layer: 28x28 grayscale image
- Convolutional Layer: conv layer with filter of the size 5x5, with valid padding(no padding), the feature maps have a size of 24x24xn1, where n1 is the number of filters used in this layer.
- Max-Pooling Layer: 2x2 window, stride 2
- Convolutional Layer: conv layer with filter of the size 5x5, with valid padding(no padding)
- Max-Pooling Layer: 2x2 window, stride 2
- Flatten Layer: Converts the feature maps 4x4 into a 1D vector with total size of 4x4xn2.
- Fully Connected Layer: the flattened vector is passed through a fully connected layer with n3 units, with ReLU activation function.
- Fully Connected Layer: passed again, applies Dropout to prevent overfitting
- Output Layer: Final Fully Connected Layer, which has 10 units corresponding to the 10 possible digit classes (0-9).
This example illustrates the typical workflow in a CNN, from input to final classification.